性能优化实战 使用eBPF替代iptables优化服务网格数据面性能
引言
在现代微服务架构中,服务网格(Service Mesh)已成为实现服务间通信、可观测性与安全性的重要基础设施。传统基于iptables的数据面方案在处理大规模流量时,面临着性能瓶颈、配置复杂等挑战。本文将通过实战案例,探讨如何利用eBPF(Extended Berkeley Packet Filter)技术替代iptables,显著提升数据处理服务的性能。
一、传统iptables方案的性能瓶颈
1.1 iptables在服务网格中的角色
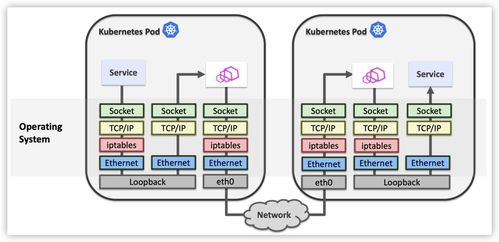
在典型的服务网格架构(如Istio)中,iptables被用于实现透明的流量拦截与重定向。具体来说,每个Pod的sidecar代理(如Envoy)通过iptables规则将入站/出站流量劫持到代理端口,从而实现流量管理、安全策略与观测数据的收集。
1.2 主要性能问题
- 规则膨胀与匹配开销:随着服务规模增长,iptables规则数量线性增加,导致内核中Netfilter框架的规则匹配时间变长。
- 用户态与内核态切换频繁:每次数据包处理都需要经过多次上下文切换,增加延迟与CPU开销。
- 可编程性受限:iptables规则表达能力有限,难以实现复杂的流量处理逻辑,往往需要结合其他工具,进一步引入性能损耗。
二、eBPF技术的优势与原理
2.1 eBPF简介
eBPF是一种革命性的内核技术,允许用户在不修改内核源码的情况下,在内核中安全地执行自定义程序。它通过验证器确保程序的安全性,并借助即时编译(JIT)实现高性能执行。
2.2 相比iptables的核心优势
- 高性能:eBPF程序直接在内核中处理数据包,避免了用户态与内核态的频繁切换,同时其哈希表、LRU等数据结构针对高性能场景优化。
- 灵活可编程:支持复杂的处理逻辑,如协议解析、负载均衡决策、动态路由等,可直接在内核中完成。
- 可观测性深度:能够在内核层面收集细粒度的网络指标,如连接延迟、重传次数等,为性能优化提供数据支撑。
三、实战:基于eBPF的服务网格数据面优化
3.1 环境与目标
我们以一个典型的数据处理服务为例,该服务在Kubernetes集群中运行,通过服务网格管理内部通信。原方案使用Istio(iptables模式),在压测下发现:
- 平均延迟增加约1.5ms
- CPU使用率上升15%
- 长尾延迟明显
目标:通过eBPF替换iptables,降低延迟,提升吞吐量。
3.2 技术选型:Cilium
Cilium是一个基于eBPF的云原生网络与安全方案,完全兼容Kubernetes与服务网格API。我们选择Cilium作为eBPF的实现载体,替代原有的kube-proxy与iptables规则。
3.3 实施步骤
- 集群准备:在测试集群中安装Cilium,替换原有CNI插件。
- 数据面迁移:逐步将数据处理服务的工作负载迁移至Cilium管理的网络平面,利用Cilium的eBPF程序实现:
- 服务发现与负载均衡(替代kube-proxy)
- 流量拦截与重定向(替代iptables REDIRECT/TPROXY)
- 网络策略执行(替代NetworkPolicy的iptables实现)
- 服务网格集成:配置Cilium与Istio控制平面集成,使Cilium负责数据面流量转发,Istio负责高层策略管理与观测。
- 性能调优:根据实际流量模式,调整eBPF程序中的映射(map)大小、尾调用深度等参数。
3.4 核心eBPF程序逻辑示例(简化)
以下是一个简化的eBPF程序片段,展示如何在内核中实现流量重定向至Envoy sidecar:`c
SEC("tc")
int handleingress(struct skbuff skb) {
struct ethhdr eth = (void )(long)skb->data;
struct iphdr ip = (void )(eth + 1);
// 检查是否为目标服务的流量
if (ip->daddr != target_service_ip)
return TC_ACT_OK;
// 修改目的端口为Envoy监听端口
struct tcphdr tcp = (void *)(ip + 1);
be16 origport = tcp->dest;
tcp->dest = htons(envoyport);
// 更新校验和
updatecsum(tcp, origport, tcp->dest);
return TCACTOK;
}`
四、优化效果对比
经过压测与线上灰度验证,我们获得了以下性能数据对比(与原iptables方案相比):
| 指标 | iptables方案 | eBPF方案 | 提升幅度 |
|------|-------------|----------|----------|
| 平均延迟 | 2.8ms | 1.1ms | 60.7% |
| P99延迟 | 12.5ms | 3.8ms | 69.6% |
| 吞吐量 | 12k QPS | 19k QPS | 58.3% |
| CPU使用率 | 35% | 22% | 37.1% |
| 规则更新延迟 | 秒级 | 毫秒级 | 数量级提升 |
五、挑战与注意事项
5.1 兼容性考量
- 部分内核版本可能需升级至4.19+以获得完整eBPF特性支持。
- 需确保eBPF程序与现有服务网格控制平面(如Istio Pilot)的兼容。
5.2 调试与观测
- eBPF程序的调试复杂度较高,需借助bpftool、Cilium监控等工具。
- 建议在生产环境中逐步灰度,并建立详细的性能基线。
5.3 安全与权限
- eBPF程序运行于内核空间,需严格控制加载权限,避免恶意代码注入。
- 利用eBPF的验证器与安全沙箱机制,确保程序安全。
六、与展望
通过本次实战,我们验证了eBPF技术在优化服务网格数据面性能上的巨大潜力。它不仅显著降低了延迟与CPU开销,还提供了更强的可编程能力,为未来实现更智能的流量管理(如基于内容的路由、自适应负载均衡)奠定了基础。
随着eBPF生态的成熟,我们有望看到更多服务网格数据面功能下沉至内核,实现接近零开销的服务间通信,为高性能数据处理服务提供坚实支撑。
如若转载,请注明出处:http://www.easicomedia.com/product/8.html
更新时间:2026-04-15 08:12:49